Why Your Robot Should Not Need to Know What a Part Looks Like Before It Picks It Up
June 22, 2026
Dr. Alejandro Astudillo
,
VP R&D | Product Research Fellow

Traditional vision systems have always made the same assumption: give the system a CAD model and it will find the part. For finished, well-defined components that can work. For raw metal blanks, tubes, pill bottles, or PCBs, it often does not. And every time it fails, a specialist has to fix it.
This is the constraint that has held vision-guided automation back for decades. Acteris was built to remove it.
The Problem
Traditional vision systems rely on model-based matching: you supply a CAD model and the system searches the scene for that exact geometry. This works reasonably well for finished, well-defined components, but breaks down for raw, unfinished parts like metal blanks. Blanks do not always conform precisely to their CAD model, and they often lack the surface texture and distinguishable shape characteristics that CAD matching depends on. The same challenge applies to tubes, pill bottles in pharmaceutical production, and PCBs in electronics manufacturing.
Beyond the blank problem, model-based matching creates three brittle dependencies that make vision-guided automation expensive to set up and painful to maintain. Without a CAD model there is no detection, so every new part triggers an engineering cycle. Parts must be held in precise fixtures to stay within the narrow range of orientations the system can handle. And thresholds and lighting conditions are hand-calibrated per part and drift over time. The cost is not the camera but the fact that every part change re-triggers a full specialist setup cycle.
What CAD-Less Vision Changes
Acteris uses an AI model built to locate featureless parts accurately in 3D without requiring a CAD model. Rather than matching against a pre-loaded geometry, the system learns to identify and localize parts based on their shape, even when parts are touching or partially overlapping, and determines which are in the best position to be picked before handing off to the robot.
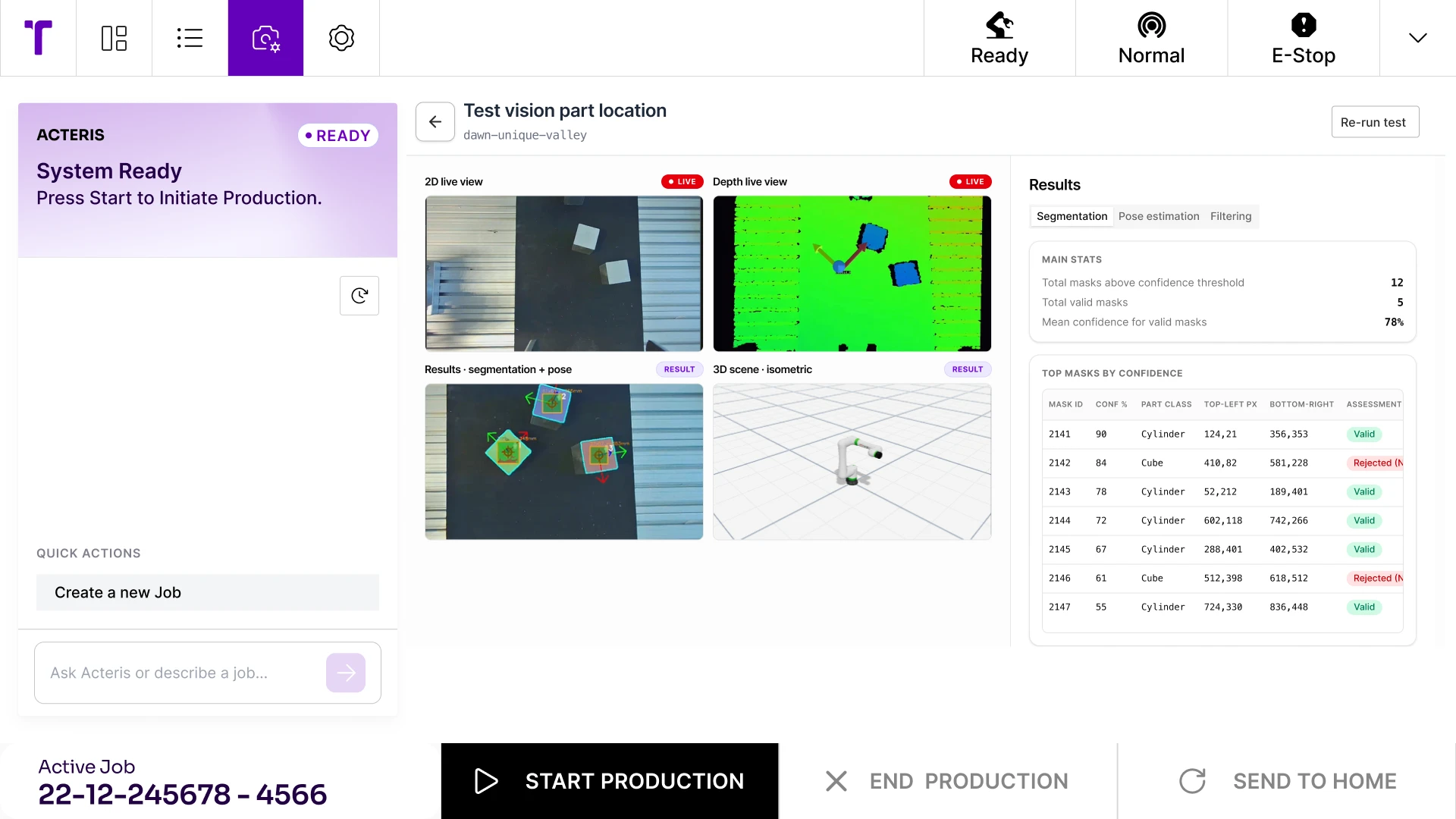
The initial training has focused on cuboids and cylinders, making it immediately applicable to metal blanks in CNC machine tending environments. But the model is designed to be trained on other part shapes as well, opening the door to applications in electronics, pharma, and beyond. The result is a vision system that does not need a new engineering cycle every time a new part is introduced.
What This Means on the Factory Floor
For manufacturers, the most immediate benefit is increased uptime. Normal variation in how parts arrive, slightly shifted, off-center, or at a different angle, no longer trips the cell. Adaptability follows: a new part type is a presentation change, not a reprogramming project.
The practical impact is significant in cells like ABB's Omnivance Collaborative Machine Tending cell, where feeding parts today requires custom grid plates, up to six drawers each with its own plate, and often a different plate per part type. CAD-less vision eliminates that dependency, allowing parts to be fed without custom plates or precise placement regardless of their orientation or position in the infeed.
To see this in action, watch the demonstration below from Elmia Automation 2026, where Acteris uses vision-guided part detection on a Universal Robots UR5e to locate and pick cuboid parts in real time, all instructed conversationally through the AI agent.
Acteris vision currently supports both fixed and on-wrist camera configurations, and the same vision software runs on whatever camera setup a line already has. Manufacturers can start with a fixed camera on a simple feeder cell and redeploy the same capability with a wrist camera when the next station needs greater reach or flexibility, without replacing or re-integrating a separate vision system.
The Bigger Picture
CAD-less vision is the first perception skill in Acteris, but what matters most about this release is not immediately visible. Beneath the surface, Acteris now has the technical infrastructure to collect and process visual feedback consistently and reliably from different vision systems through a standardized interface. That foundation is what makes everything else possible.
At T-Labs, Trener’s R&D engine that advances the core intelligence Acteris delivers into production, we are building on this toward robots that do not just see, but act, recover, and explain. For manufacturers, that means robots that detect when a pick did not go as expected and recover autonomously, cells that adapt to new parts and layouts without reprogramming, and systems that can show operators why a decision was made so they can trust, debug, and sign off on it.
Perception is one of three pillars of our Physical AI offering, alongside motion skills and learning policies. The infrastructure now in place is the foundation for upcoming capabilities including learning policies, visual awareness, and visual servoing. The foundation is in place. What gets built on it will change what robots can do in production.